Codificación de un programa
Una vez que los algoritmos de una aplicación han sido diseñados, ya se puede iniciar la fase de codificación. En esta etapa se tienen que traducir dichos algoritmos a un lenguaje de programación específico, en nuestro caso C; es decir, las acciones definidas en los algoritmos las vamos a convertir en instrucciones, también llamadas sentencias, del lenguaje C.
EJEMPLO Al codificar en C el algoritmo del programa Sumar, visto en el aparado anterior (Diseño), se escribirá algo parecido a:
#include <stdio.h>
int main()
{
int a, b, c;
printf( "\n Introduzca el primer n%cmero (entero): ", 163 );
scanf( "%d", &a );
printf( "\n Introduzca el segundo n%cmero (entero): ", 163 );
scanf( "%d", &b );
c = a + b;
printf( "\n La suma es: %d", c );
return 0;
}Para codificar un algoritmo hay que conocer la sintaxis del lenguaje al que se va a traducir. Sin embargo, independientemente del lenguaje de programación en que esté escrito un programa, será su algoritmo el que determine su lógica. La lógica de un programa establece cuáles son sus acciones y en qué orden se deben ejecutar. Por tanto, es conveniente que todo programador aprenda a diseñar algoritmos antes de pasar a la fase de codificación.
Lenguajes de programación
Un lenguaje de programación se puede definir como un lenguaje artificial que permite escribir las instrucciones de un programa informático, o dicho de otra forma, un lenguaje de programación permite al programador comunicarse con la computadora para decirle qué es lo que tiene que hacer. Con esta finalidad, el hombre ha inventado muchos lenguajes de programación, ahora bien, todos ellos se pueden clasificar en tres tipos principales: máquina, de bajo nivel y de alto nivel.
El lenguaje máquina es el único que entiende la computadora digital, es su "lenguaje natural". En él solamente se pueden utilizar dos símbolos: el cero (0) y el uno (1). Por ello, al lenguaje máquina también se le denomina lenguaje binario. La computadora solo puede trabajar con bits, sin embargo, para el programador no resulta fácil escribir instrucciones tales como:
10100010
11110011
00100010
00010010
Por esta razón, se inventaron lenguajes de programación más entendibles para el programador. Así, aparecieron los lenguajes de bajo nivel, también llamados lenguajes ensambladores, los cuales permiten al programador escribir las instrucciones de un programa usando abreviaturas del inglés, también llamadas palabras nemotécnicas, tales como: ADD, DIV, SUB, etc., en vez de utilizar ceros y unos. Por ejemplo, la instrucción:
ADD a, b, c
Podría ser la traducción de la acción:
c ← a + b
Dicha acción está presente en el algoritmo Sumar del apartado anterior (Diseño), la cual indicaba que en el espacio de memoria representado por la variable c se debe almacenar la suma de los dos números guardados en los espacios de memoria representados por las variables a y b.
Un programa escrito en un lenguaje ensamblador tiene el inconveniente de que no es comprensible para la computadora, ya que, no está compuesto por ceros y unos. Para traducir las instrucciones de un programa escrito en un lenguaje ensamblador a instrucciones de un lenguaje máquina hay que utilizar un programa llamado ensamblador, como se muestra en la siguiente figura:
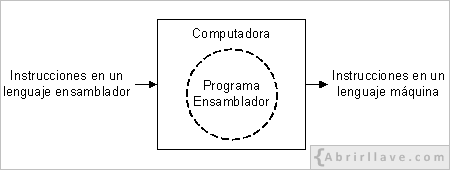
Una dificultad añadida a los lenguajes binarios es el hecho de que son dependientes de la máquina –o mejor dicho, del procesador–, es decir, cada procesador utiliza un lenguaje máquina distinto –un juego de instrucciones distinto– que está definido en su propio hardware. En consecuencia, un programa escrito para un tipo de procesador no se podrá usar en otro equipo que utilice un procesador distinto, ya que, el programa no será portable o transportable. Para que dicho programa pueda funcionar en una segunda computadora, habrá que traducir todas las instrucciones escritas en el lenguaje máquina del primer equipo al lenguaje binario de la segunda computadora, lo cual supone un trabajo muy costoso y complejo para el programador.
Igualmente, puesto que las instrucciones que se pueden escribir en un lenguaje ensamblador siempre están asociadas a las instrucciones binarias de una computadora en concreto, los lenguajes ensambladores también son dependientes del procesador. Sin embargo, los lenguajes de alto nivel sí que son independientes del procesador, es decir, un programa escrito en cualquier ordenador con un lenguaje de alto nivel podrá transportarse a cualquier otra computadora, con unos pequeños cambios o incluso ninguno.
Un lenguaje de alto nivel permite al programador escribir las instrucciones de un programa utilizando palabras o expresiones sintácticas muy similares al inglés. Por ejemplo, en C se pueden usar palabras tales como: case, if, for, while, etc. para construir con ellas instrucciones como:
if ( numero > 0 ) printf( "El n%cmero es positivo", 163 );
Que traducido al castellano viene a decir que, si numero es mayor que cero, entonces, escribir por pantalla el mensaje: "El número es positivo".
Ésta es la razón por la que a estos lenguajes se les considera de alto nivel, porque se pueden utilizar palabras de muy fácil compresión para el programador. En contraposición, los lenguajes de bajo nivel son aquellos que están más cerca del "entendimiento" de la máquina. Otros lenguajes de alto nivel son: Ada, BASIC, COBOL, FORTRAN, Pascal, etc.
Otra característica importante de los lenguajes de alto nivel es que, para la mayoría de las instrucciones de estos lenguajes, se necesitarían varias instrucciones en un lenguaje ensamblador para indicar lo mismo. De igual forma que, la mayoría de las instrucciones de un lenguaje ensamblador, también agrupa a varias instrucciones de un lenguaje máquina.
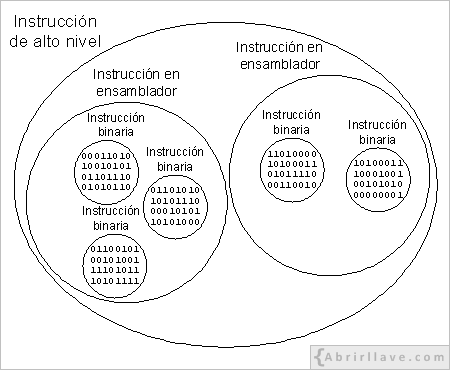
Por otra parte, un programa escrito en un lenguaje de alto nivel tampoco se libra del inconveniente que tiene el hecho de no ser comprensible para la computadora y, por tanto, para traducir las instrucciones de un programa escrito en un lenguaje de alto nivel a instrucciones de un lenguaje máquina, hay que utilizar otro programa que, en este caso, se denomina compilador.
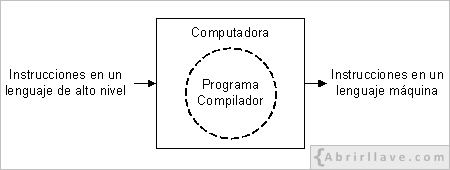
Compiladores e intérpretes
Al conjunto de instrucciones escrito en un lenguaje de alto nivel se le llama código fuente del programa. Así pues, el compilador es un programa que recibe como datos de entrada el código fuente de un programa escrito por un programador, y genera como salida un conjunto de instrucciones escritas en el lenguaje binario de la computadora donde se van a ejecutar. Al conjunto de instrucciones generado por el compilador se le denomina código objeto del programa, también conocido por código máquina o código binario, ya que, es, en sí mismo, un programa ejecutable por la máquina.
Normalmente, un programador de C utilizará un programa de edición para escribir el código fuente de un programa, y lo guardará en un archivo con extensión (.c). Por ejemplo, "Sumar.c". A continuación, un compilador de C traducirá el código fuente a código objeto, guardándolo con otra extensión, que, dependiendo del sistema operativo puede variar. Por ejemplo, en Windows, se guardará con la extensión (.obj), abreviatura de object.
Por otro lado, existe un tipo de programas llamados intérpretes, los cuales también sirven para traducir el código fuente de un programa a código objeto, pero, su manera de actuar es diferente con respecto a la de un compilador.
El funcionamiento de un intérprete se caracteriza por traducir y ejecutar, de una en una, las instrucciones del código fuente de un programa, pero, sin generar como salida código objeto. El proceso que realiza un intérprete es el siguiente: lee la primera instrucción del código fuente, la traduce a código objeto y la ejecuta; a continuación, hace lo mismo con la segunda instrucción; y así sucesivamente, hasta llegar a la última instrucción del programa, siempre y cuando, no se produzca ningún error que detenga el proceso. En un programa pueden existir, básicamente, tres tipos de errores: de sintaxis, de ejecución y de lógica.
Tipos de errores
Cuando en alguna instrucción del código fuente de un programa existe un error de sintaxis, dicho error impedirá, tanto al compilador como al intérprete, traducir dicha instrucción, ya que, ninguno de los dos entenderá qué le está diciendo el programador. Por ejemplo, si en vez de la instrucción:
printf( "\n Introduzca el primer n%cmero (entero): ", 163 );
Un programador escribe:
prrintf( "\n Introduzca el primer n%cmero (entero): ", 163 );
Cuando el compilador o el intérprete lean esta línea de código, ninguno de los dos entenderá qué es prrintf y, por tanto, no sabrán traducir esta instrucción a código máquina, por lo que, ambos pararán la traducción y avisarán al programador con un mensaje de error.
En resumen, los errores de sintaxis se detectan en el proceso de traducción del código fuente a código binario. Al contrario que ocurre con los errores de ejecución y de lógica, que sólo se pueden detectar cuando el programa se está ejecutando.
Un error de ejecución se produce cuando el ordenador no puede ejecutar alguna instrucción de forma correcta. Por ejemplo, la instrucción:
c = 5 / 0;
Es correcta sintácticamente y será traducida a código binario. Sin embargo, cuando la computadora intente realizar la división:
5 / 0
Se producirá un error de ejecución, ya que, matemáticamente, no se puede dividir entre cero.
En cuanto a los errores de lógica, son los más difíciles de detectar. Cuando un programa no tiene errores de sintaxis ni de ejecución, pero, aún así, no funciona bien, esto es debido a la existencia de algún error lógico. De manera que, un error de lógica se produce cuando los resultados obtenidos no son los esperados. Por ejemplo, si en vez de la instrucción:
c = a + b;
Un programador hubiera escrito:
c = a * b;
Hasta que no se mostrase por pantalla el resultado de la operación, el programador no podría darse cuenta del error, siempre que ya supiese de antemano el resultado de la suma. En este caso, el programador podría percatarse del error fácilmente, pero, cuando las operaciones son más complejas, los errores de lógica pueden ser muy difíciles de detectar.
Fases de la puesta a punto de un programa
Además de todo lo visto hasta ahora, también hay que tener en cuenta que una aplicación informática suele estar compuesta por un conjunto de programas o subprogramas. Por tanto, el código objeto de todos ellos deberá ser enlazado (unido) para obtener el deseado programa ejecutable. Para ello, se utiliza un programa llamado enlazador, el cual generará y guardará, en disco, un archivo ejecutable. En Windows, dicho archivo tendrá extensión (.exe), abreviatura de executable.
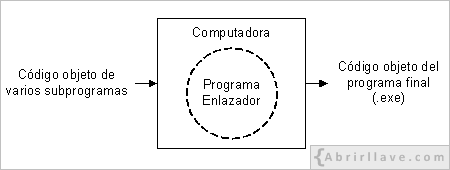
Debido a que los lenguajes de alto nivel son portables, un programa escrito en este tipo de lenguaje podrá ejecutarse en cualquier otra máquina. Pero, esto no es del todo cierto, ya que, para que esto sea posible entre máquinas de distinto tipo, el código fuente de dicho programa deberá compilarse y enlazarse de nuevo en esa otra máquina. Esto quiere decir que, en realidad, son portables los códigos fuentes –aunque sea con unos pequeños cambios– pero no los códigos binarios.
Para la mayoría de los programas escritos en lenguajes de programación de alto nivel, el proceso de obtención del código ejecutable consta de tres fases: edición, compilación y enlace. Sin embargo, algunos lenguajes, y C es pionero en este sentido, requieren una fase más, llamada preproceso. En esta etapa participa un programa llamado preprocesador. El preproceso siempre se realiza antes que la compilación, de hecho es el propio compilador quien llama al preprocesador antes de realizar la traducción del código fuente a código objeto.
El preprocesador sirve para realizar una serie de modificaciones en el código fuente escrito por el programador. Dichas modificaciones sirven, entre otras cosas, para que más tarde el enlazador pueda unir el código objeto del programa que se está desarrollando con el código objeto de otros programas.
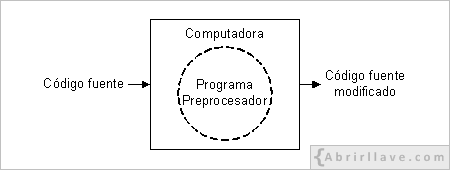
En realidad, el preproceso no es visible al programador, ya que, el preprocesador no guarda en disco ningún archivo, simplemente modifica el código fuente y se lo pasa al compilador para que éste lo traduzca.
Gráficamente, el proceso completo de puesta a punto de un programa escrito en C se puede representar de la siguiente forma:
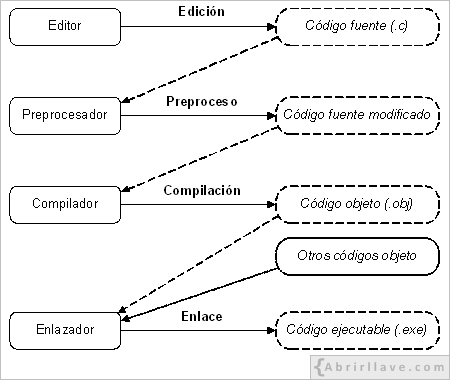
Finalmente, para que el código ejecutable de un programa se ejecute en la computadora, es necesario que otro programa del sistema operativo, llamado cargador, lo lleve a la memoria principal de la misma. A partir de ese momento, la CPU empezará a ejecutarlo.
Entornos Integrados de Desarrollo (EID)
En el mercado existen aplicaciones informáticas, llamadas Entornos Integrados de Desarrollo (EID), que incluyen a todos los programas necesarios para realizar todas las fases de puesta a punto de un programa; en el caso de C se necesita un editor, un preprocesador, un compilador y un enlazador. Además, un EID suele proporcionar otras herramientas software muy útiles para los programadores, tales como: depuradores de código, ayuda en línea de uso del lenguaje, etc. Todo ello, con el fin de ayudar y facilitar el trabajo al programador.
Depuradores de código
Un depurador de código permite al programador ejecutar un programa paso a paso, es decir, instrucción a instrucción, parando la ejecución en cada una de ellas, y visualizando en pantalla qué está pasando en la memoria del ordenador en cada momento, esto es, qué valores están tomando las variables del programa. De esta forma, el programador puede comprobar si el hilo de ejecución del programa es el deseado. De no ser así, esto puede ser debido a diversas causas. Lo primero que hay que hacer es comprobar si el algoritmo se ha traducido correctamente, ya que, al programador se le puede haber pasado por alto alguna instrucción, o puede que haya puesto un signo más (+) donde debería ir un signo menos (-), etc. En estos casos, corregir el error solamente afectará al código fuente del programa. Sin embargo, si la traducción del algoritmo es correcta, entonces el problema estará, precisamente, en el diseño de dicho algoritmo, el cual habrá que revisar, modificar y volver a codificar.